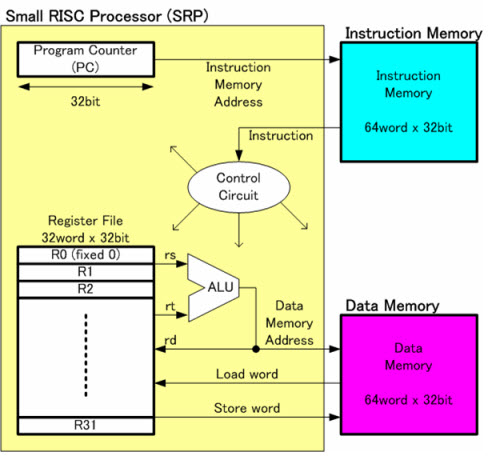
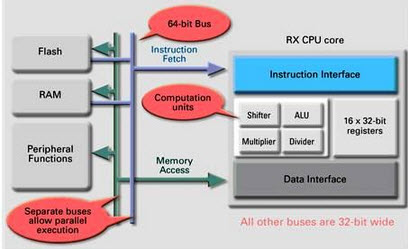
Older and simple systems have a "FLAT memory model"
Flat memory model or linear memory model refers to a memory addressing paradigm in which memory appears to the program as a single contiguous address space. The CPU can directly (and linearly) address all of the available memory locations without having to resort to any sort of memory segmentation or paging schemes.
Memory management and address translation can still be implemented on top of a flat memory model in order to facilitate the operating system's functionality, resource protection, multitasking or to increase the memory capacity beyond the limits imposed by the processor's physical address space, but the key feature of a flat memory model is that the entire memory space is linear, sequential and contiguous from address zero to MaxBytes.
In a simple controller, or in a single-tasking embedded application, where memory management is not needed nor desirable, the flat memory model is the most appropriate, because it provides the simplest interface from the programmer's point of view, with direct access to all memory locations and minimum design complexity.
The problem with this type of allocation is (external) fragmentation of memory: sometimes, there is enough free memory in the system, but it is fragmented over several locations so that a contiguous block cannot be found to satisfy a request.
- Memory and Peripheral Share.
- Memory will be mapped to ONE part
- Peripherals will be mapped to another
- All processes and OS share the same memory.
- No Memory protection. User-space and corrupt Kernel Memory.
Another Advance thing is "PAGED memory model"
Two important feature of Paged memory model is "PAGING" and "Virtual Memory". This is implemented in the Memory Management Subsystem of any operating system. We will discuss more on "LINUX-ARM" based memory management in this article.
This is a memory management technique that allows non-contiguous memory allocations to processes and avoids the problem of external fragmentation. Most modern operating systems use paging. With paging, the physical memory is divided into frames, and the virtual address space of a process is divided into logical pages
- Suitable for multitasking, general operating system design, memory/resource protection and allocation.
- More CPU real estate, somewhat lower speed
- More complex to program.
- Rigid page boundaries, not always the most memory efficient.
Features of the model
- Virtual Memory is used here where Virtual Addresses are mapped to Physical Addresses using MMU.
- Maps Virtual Address to Physical RAM area.
- Maps Virtual Address to Peripheral Device Memory
- GPU, PCI On-SOC IP blocks are examples.
- Each process can have a different memory mapping. One process address space is separate from others.
- Kernel Area is invisible to User-space Area
- Physical RAM area can be mapped to multiple process address space to create shared memory among processes.
- Memory mapping may have read/write permissions.
- Memory can be moved/swapped in/out for disks.
- Avoid the problem of external fragmentation since this is non-contiguous memory approach.
Memory Management Unit and Virtual Memory
The memory management unit(MMU) hardware is responsible for implementing Virtual Memory.
- This sits between the CPU core and Physical Memory.
- Most often MMU is part of CPU core itself. [As in case of ARM]
- Separate from RAM controller - DDR controller is a separate IP.
- Transparently handles all memory accesses from load-store instructions.
- Maps access from Virtual Address to system RAM.
- Maps access from Virtual Address to Memory Mapped I/O or Hardware
- Handles Permission and Generates exception on illegal access or invalid virtual address. In other words, If the virtual address is not in the TLB, the MMU will generate a page fault exception and interrupt the CPU.
Image by Prof Matt Welsh, Harvard University
How does Virtual Address get created?
- Processor core generates the Virtual Address.
- MMU takes the upper bits of Virtual Address and replaces them with the contents of the relocation register and thus it gets the Physical Address.
- The lower portion of the virtual address is offset that translates an address in Physical Memory.
- A single relocation register can translate a singe area of virtual memory called as Page. The corresponding physical memory area is called a Page Frame.
How does so many Pages are handled in a multithreading environment?
A single relocation register can translate only a single Page into a PageFrame. The ARM MMU hardware has multiple relocation registers supporting the translation
of virtual to physical memory. The MMU needs many relocation registers to map so many pages. ARM MMU has a set of 64 relocation register which
caches(temporary stores) the translation of recently
accessed page which is called TLB(Translation Look-Aside Buffer).
In addition to TLB, the Linux kernel maintains a Page Table(Tables in Main Memory), this also has the mapping data for the recently accessed page again used by MMU. Each entry in the Page table also has details on access permission/cache/write buffer configurations etc.
Why do we need TLB? Can we only use Linux's Page table?
The TLB is used to reduce the time taken to access the memory locations in the page-table method. The TLB is a cache or temporary storage of the Linux's page table, representing only a subset of the page-table contents.
TLB is checked for Page Faults:-
- If the virtual address is not in the TLB, the MMU will generate a page fault exception and interrupt the CPU.
- If the address is in the TLB, but the permissions are insufficient, the MMU will generate a page fault.
Note: MMU is a piece of Hardware, it doesn't act automatically. Again Kernel has relevant code to use MMU for implementing the complete Memory Management functionality. MMU can be configured/initialized/switched off just like other On-chip components.
Summary:
Flat Memory Model is like where there is one-to-one mapping Virtual to Physical Address. This is simple without any overhead of Memory Management. However, this approach doesn't work for complex multithreaded and multi-core system as there should be some external software/hardware component who has to manage the memory for better usage among so many processes.
- Risk of Fragmentation of Memory.
- Risk of Corruption of Other Process Address Space.
- Lesser control in applying write/read permissions for memory etc.
Paged Memory Model not only gives us more control/security on Memory and its usage - per process wise but also it relives from the risk of over-fragmentation This becomes even more valid especially in event-driven embedded systems where a system is rarely restarted often - an example would be a mobile phone software.
References:-
- ARM System Developer's Guide by Andrew,Dominic and Chris
- https://www.cse.iitb.ac.in/~mythili/teaching/cs347_autumn2016/